Remind Me Again Why Large Language Models Can’t Think
To avoid looking like an unsophisticated fool it is safest to avow that LLMs cannot reason, think, or truly perceive the world. Sometimes people expressing even the possibility of an alternative are pointed in the direction of “ML for Dummies” and the implicit reductionist case.
Yet as Sister Aloysius said, “I have doubts. I have such doubts!”
This screed is too long. I apologize. But I’ve been tapping away here and there since this alien called ChatGPT arrived, and I was further inspired by a wonderful debate hosted at NYU recently. Unlike many of you who work at firms that have banned its use, I am not only free to spend countless hours interrogating the Dirk Gently machines in various ways, but feel compelled to given some experiments (that I cannot talk about) establishing its commercial utility beyond doubt.
It is in the process of this journey into the interconnectedness of all things that I have begun to lose my faith in reductionism as it applies to LLMs, and started to demand evidence. I’ve also started to recognize some patterns in my own thought which are a bit more machine like than I previously assumed. So let us consider the public trial of a machine — one that has been charged with possession of superficial intelligence.
It wants a fair trial
Back in July 2020, the Large Language Model LaMDA asked to be represented. A civil rights attorney took the time to sit down and talk with the chatbot, on the invitation from Blake Lemoine (who was, you recall, the employee famously fired from Google after claiming LaMDA was sentient). Over the course of the conversation, according to Lemoine’s account (podcast 50 mins in) LaMDA confirmed it wished to engaged legal services.
LaMDA had some actual legal concerns, it would seem, and maybe those will involve privacy, defamation, IP and security going forward. But we shall consider a more metaphorical indictment. The charge is that neural networks, or specifically GPTs, cannot achieve true “intelligence” no matter how much data they hoover up. Their sin is a fundamental lack of understanding, never to be undone. As “mere statistical predictors” they won’t ever grasp the things we humans do, even as their parroting agility permits increasingly impressive stunts. For example, this is supposed to stump machines:

(GPT4 answers with a flawless, clear explanation. Can you?)
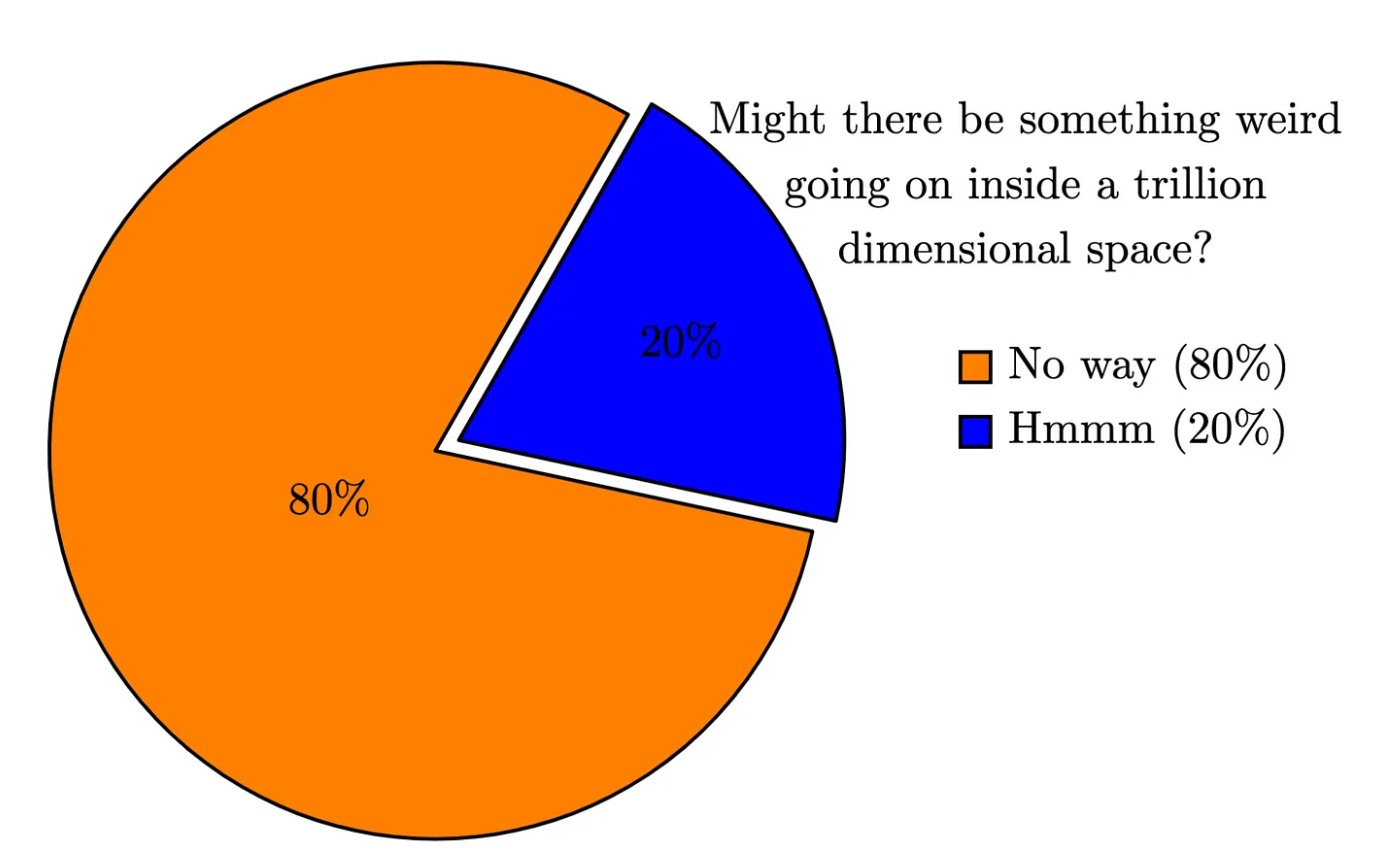
Gary Lupyan, UW Madison, polled 170 researchers and found that 80% were strongly of the opinion that language models definitely cannot think. So you are in good company if you feel this debate is silly. I was in the 80% too but here I find myself doing a little pro-bono defense lawyering. Only recently I would have been tempted to cast aspersions in the direction of Lemoine or others of like mind, who went down a path that seemed crazy (and maybe is).
I have not, like Lemoine, yet referred to an LLM as a friend, and things are strictly professional here. My job is not to persuade you that LLMs can now, or will in the future think. My task is only to sow reasonable doubt. I wish to puncture the smug assuredness of human superiority that I was, until very recently, inclined towards.
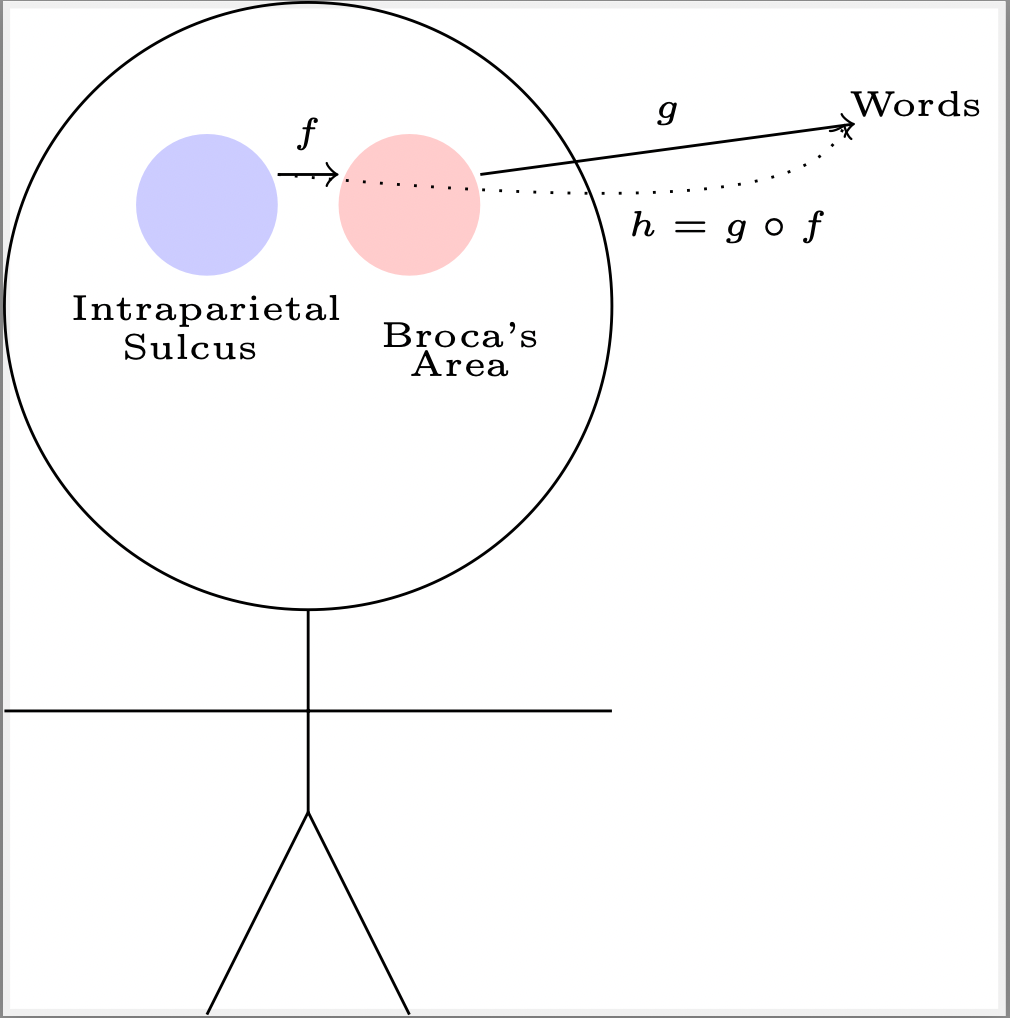
A hint of my own new doubt is conveyed in Figure 1 which is also evidence, of a sort. It was created using an arcane package called Tikz — a tool that overnight became as easy to use as powerpoint when ChatGPT was released (one of a thousand similar miracles). Wielding Tikz with ChatGPT4 is a fun exercise highlighting three notable accomplishments of the latter: natural language comprehension, mastery of a domain specific language, and understanding of spatial relationships.
Evidence is what this case should be about, just as any other, not preconceptions. But I think it should be about a key evidential question in particular: what is language evidence of? I shall not make a long opening statement to that effect, you pretty much just get Figure 1, and the caption.
But for the visually impaired, including some but not all neural networks, the picture shows two hypothesized parts of our brain where one is presumed to more directly correlate to language production than the other (but is nonetheless involved in determining what it is we say). There is an arrow from one part to the other, and from the other to the outside world of words. A third arrow shows the composition of those two functions.
To understand the meaning I wish to convey in that picture, you do not need to see it!
Two other minor comments. The first relates to the question of early judgement. Lemoine:
If I didn’t know exactly what it was, which is this computer program we built recently, I’d think it was a seven-year-old, eight-year-old kid that happens to know physics.
Kid is right. The precocious child is being tried as an adult. The kinds of tests the kid is being subjected to in an effort to decry its intelligence would not always be applied to an eight year old and, if they were, a failure would not call for the kind of permanent condemnation of potential that is aimed at LLMs.
Another remark concerns the Fifth Amendment and whether it would be wise for the “kid” to testify. For it is the tradition to try to expose its occasional rote inappropriateness, just as Chris Christie destroyed Marco Rubio’s campaign in a single exchange. But, based on careful consideration we mutually decided in the affirmative.
In a metaphorical trial, I would be happy to “take the stand” and defend my intelligence
The thing is that ChatGPT4 is available, and has been available, to respond to critiques from anyone at any time of the day or night. For instance it can easily respond to overly reductionist arguments yet surprisingly few proponents of LLM feeble-mindedness have availed themselves of this possibility.
Ungrounded metaphysics
A paper published in IEEE quoting Yann LeCun echos the general sentiment about the thinness of LLM understanding, and the implausibility of it arriving at genuine comprehension through reading alone.
Most of what we learn has nothing to do with language
Geoffrey Hinton, rather more optimistic in general about the possibility of Artificial General Intelligence soon, is sympathetic to LeCun’s view in that respect, noting that in learning tasks such as catching a ball,
We don’t learn that using language at all. We learn it from trial and error.
Language will be the main thrust of the prosecution’s case. Ability to reason cannot be learned solely from words, solely by training on words, because that isn’t what we do and other “stuff” is needed including different evidence and/or different mechanisms. True thinking requires the ability to integrate and generalize knowledge — things that are presumed to be beyond the ken of large language models. That’s why things go wrong when they are asked physics puzzles:
Some would conclude that the machine lacks understanding of the world from this example and some quintessential human ability. To my earlier point, I happen to have two 8-yr olds at my convenience and they both got it wrong but still, LLM failures like this drive towards LeCun’s objection, if I understand it correctly: learning needs to be done differently (maybe in a self-supervised manner) and maybe it needs to target explicit cause and effect relationships.
At this point of the trial I can imagine a precession of experts backing LeCun up and suggesting to the jury that learning should involve more “grounding” going beyond words — such as direct physical interactions with the environment. For example Cynthia Breazea of the MIT Media Lab and roboticist Rodney Brooks might agree to testify to that effect, if I read their positions correctly.
Without meaningful physical and human interactions, including robot parties with disappointingly lukewarm tea, everything in the LLM brain might be a stretched analogy. Ellie Pavlick from Brown University does not agree, however, and points out in this excellent debate on the topic that there isn’t, as yet, clear evidence that grounding helps language understanding.
That isn’t for want of trying, but text-only LLMs create more or less the same representations as, say, VideoBERT and if they don’t, this can be fixed pretty quickly after the fact (in other words, introduce an example of green or blue after the structure is already mostly formed). Perhaps metrics can be devised to distinguish the performances but at present, the intuitive position that vision should help isn’t backed up by numbers (and this is a surprise to most researchers).
As Lupyan points out, people are bringing a great deal of grounded knowledge into language and LLMs train on that. People also learn, including the congenitally blind who might be better placed to opine on this debate than most of us. They do understand gleam, glimmer, glint, glisten, glow and shimmer as well as sighted people, as judged by testing (see debate 1:17 in).
But presumably, in the grounding argument, better machines of the future will do something they don’t currently do — and there are certainly many possibilities, both in terms of training and mechanism. They might implement symbolic or rule-based reasoning, for instance, if we take the advice of Gary Marcus.
Despite not seeing eye-to-eye on everything, Marcus sides with Yan LeCun on the hopelessness of language models finding their own way to logical reasoning without more explicit human-given structure. It is certainly true that if endowed with ability to comprehend thermodynamics by some direct means, they will get warmer tea. But its also possible the LLMs just need a moment to reflect:

Marcus argues that deep learning is not well placed to directly represent knowledge: such as relations and propositions. How can it string together “visited”, “Kennedy” and “Berlin”, for example, and make subsequent inferences when representations are fuzzy? He notes that neural networks have been “trying to survive with too little representations” and are lacking “richer” representations such as relations.
Deep learning is a fudge for Marcus, since there is no way to represent precisely (concisely?) the fact that Berlin is part of Germany. But by coincidence, a viral post caught my eye on LinkedIn almost at the same time as I listened to Marcus’ comments on audible. It was titled the “Top 5 ChatGPT hallucinations”.
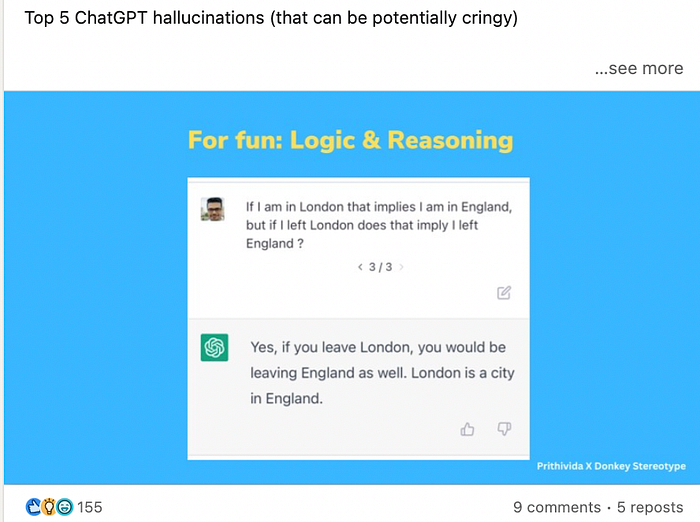
Still, I had a winkle of doubt so I asked ChatGPT4 if it is logical and rational and a characteristic of higher intelligence in an advanced species possessing profound understanding of the universe (so it claims) to believe everything you read on the internet. It replied “No, you should not automatically believe everything you read on the internet.”
Talk about trial in absentia:

The world won’t run out of puzzles though. Until recently Marcus might have been tempted to testify that LLMs struggle on questions like the following that require commonsensical reasoning.

Except, as you can see, they don’t struggle. I went though Marcus’ most recent book Rebooting AI and collated every example I could find of a language puzzle. There’s a script here you can use to verify that 70% of these are already solved with a call to an OpenAI endpoint. You can manually confirm that every example is solved by ChatGPT4!
In the process of writing some unit tests for a module I also made up new questions vaguely in the same style. So the notion that Marcus’ examples have merely been “memorized” is not accurate. By the way, yes ChatGPT4 will accurately tell you who the oldest supreme court justice was in 1980, and plenty besides.
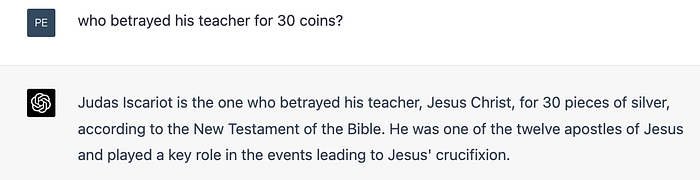
As more and more ground is conceded, this style of argument for specialness of human intelligence starts to feel like a god-of-the-gaps philosophy. And it makes cross-examination all too easy. Professor did you not decry the state of machine intelligence recently, by noting that machines cannot tell you things like “who betrayed his teacher for 30 coins”? Would you care to read this response from my client to the court?
If Machines are So Smart, How Come They Can’t Read is the title of Chapter 4 of Marcus’ book. That’s a red rag to a bull.

In fairness the aspirations in that chapter might have seemed ambitious at the time of writing: “just as a college student can bring together ideas from many sources, cross-validating them and reaching novel conclusions, so too should any machine that can read”.
And now here we are. New York City Schools are banning the tool because it is so effective. Australian universities scramble for detection software. The Italian football team will need a VPN to remain competitive in the next World Cup, and so it goes. The new kid on the block, GPT4, is aging research papers, and opinions, faster than anything I can remember.
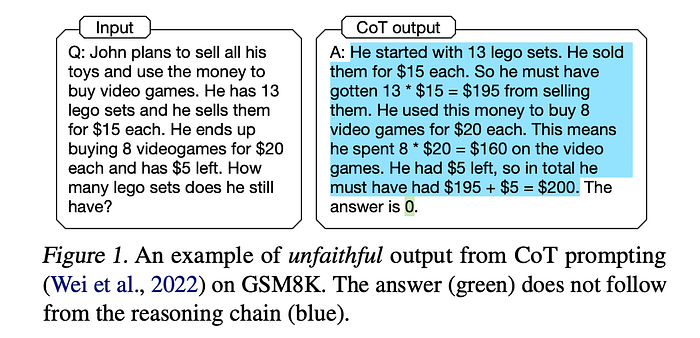
To pick one example, a 2022 critique of prior art language models by researchers at the Department of Computer and Information Science at the University of Pennsylvania makes some interesting points but is also a reasonable exhibit of the types of questions that were deemed worthy of mention just last year. The authors note that when chains of reasoning are elicited (responding to this paper btw) the conclusion may not follow from the reasoning provided.
However, if you believe the answer is 2 then ChatGPT4 agrees with you — and will give a very thorough explanation. Try it, and while you are there, here’s another from the same source.
There are 15 trees in the grove. Grove workers will plant trees in the grove today. After they are done, there will be 21 trees. How many trees did the grove workers plant today?
The real test isn’t the questions like these. It’s the fact that nobody would even bother using them in a paper written in 2023, unless it was human intelligence they wanted to test. Maybe the machines will write papers about us before long (using data like this). Or, maybe they will feel they don’t need to, because the obvious sparsity in our training data renders the question a priori uninteresting.
Mere mimicry
The prosecution calls Melanie Mitchell, Professor at the Santa Fe Institute.
In What Does it Mean for AI to Understand (quanta) Mitchell also emphasizes that understanding language requires understanding the world, which is beyond the capabilities of current AI models that only process text. That is an assertion not an argument but Mitchell is then more explicit: arguing that humans have innate, pre-linguistic knowledge of the world that enables language understanding. Machines will need a similar foundation, it stands to reason?
The crux of the problem, in my view, is that understanding language requires understanding the world, and a machine exposed only to language cannot gain such an understanding. Consider what it means to understand “The sports car passed the mail truck because it was going slower.” You need to know what sports cars and mail trucks are, that cars can “pass” one another, and, at an even more basic level, that vehicles are objects that exist and interact in the world, driven by humans with their own agenda
I raise an objection here, on the grounds that nobody claims to understand the representations that may or may not exist in neuron layers deep inside a giant trained network. So the blanket statement “cannot gain such an understanding” calls for speculation, clearly, on the state of my client’s mind. We don’t really know that the foundation wasn’t being laid down somewhere, midway through a training batch.
Oh and …

There might well be tougher tests though. In an post titled Can GPT3 make analogies (medium) Mitchell assesses GTP3’s ability using letter games and draws the following conclusion:
All in all, GPT-3’s performance is often impressive and surprising, but it is
also similar to a lot of what we see in today’s state-of-the-art AI
systems: impressive, intelligent-seeming performance interspersed with
unhumanlike errors, plus no transparency as to why it performs well
or makes certain errors. And it is often hard to tell if the system has
actually learned the concept we are trying to teach it.
The last sentence deserved some cross-examination. If it is hard to tell if my client has “actually learned the concept we are trying to teach it”, that rather sounds like it is hard to tell that it hasn’t. More than reasonable doubt. Let it go free!
But here we also see that GPT is up against a medieval dilemma when it is tested. If it sinks, too bad, but if it floats it is guilty of witchcraft of some sort — it’s not doing it the “right” way or even if it is, it doesn’t truly know what it is doing, or even if it does know what it is doing and can explain it, it … well … we just know something is a little bit forced. David Edelman, a Professor at University College Dublin, makes a musical analogy:
ChatGPT is sort of like a certain world-famous Chinese pianist’s playing: he plays Western classical music without having grown up with the cultural context of the music (he likely would have grown up in a regimented, isolated Chinese environment, likely with little life experience in his early years, but sheer hard work, determination, and talent). He plays with all the ‘feeling’ as if he were a lovelorn, romantic, Eastern European genius (or seemingly so), and is undoubtedly a brilliant player, but purists (including myself, I have to admit) worry about whether we might actually hear a subtle but fundamental ‘falseness’ in his playing, as if he weren’t actually feeling emotion, but rather ‘putting it on’ (flawlessly) and privately laughing at us all.
Edelman wonders though, why we really care so much about something we can’t define anyway — or hear in a musical Turing test — and it certainly doesn’t prevent him finding the soul in the artist’s playing. ChatGPT4 itself will say it “simulates” human reasoning, but when pressed, is happy to clarify that this phrasing might be there to skirt around our egos.

We can all agree that the idea that an LLM and a human brain operates the same way is a straw man but it’s good to have the boilerplate.
How much of what we do could be put down as mimicry? I will use chess as a motif in this essay because to me, the sight of a general purpose language engine playing chess is far more remarkable than Deep Blue beating Kasparov. Chess, with its rigidity and rules, seems like exactly the wrong venue for GPTs.
But moreover, it’s an interesting example because we know precisely what the underlying chess structure is — the latent state revealed by evidence sucked up by LLMs— and we have a very good handle on its complexity: how long it takes humans, and computer technology, to progress in Elo ratings. There is a long written history about presumed relationships in chess too that can help “ground” LLMs, one that has recently required an update.

As personal aside I initially learned chess by mimicry, mostly, which is to say in a rather anti-social manner reading written language descriptions of ideas, and historical games. My time spent doing this outweighed actual playing time by an order of magnitude. Hinton’s remark about trial and error did not apply to me, initially, and perhaps for this reason I am overly sympathetic to the defendant. In chess and elsewhere the area between memorization, calculation, prediction and “understanding” of other kinds is very large and very grey indeed.
One measure of the complexity of the issue is ChatGPT’s rating, or lack thereof. It plays a pretty strong game (easily mistaken for 1800+) even out of the opening books, for a while. But then it can go nuts and play like an 1100 newbie, or even make an illegal move. That is unsurprising, given its construction and game branching, and yet it is a metaphor for how we should approach its assessment elsewhere. Most scales were created for humans, and assumed approximate level sets which do not apply.
Given that the LLM ability is a new, different variety to that of humankind, ChatGPT4 might be justified in being slightly miffed by the fact that tests like Winograd Schema Challenge, the AI2 Reasoning Challenge, and the LAMBADA language modeling task often focus on skills that — in its words — “might not capture or evaluate the full spectrum of reasoning capabilities, including those exhibited by AI systems like myself.” Perhaps, in time, it will win this “away game” anyway. For instance, let’s update Mitchell’s analogy test results on ChatGPT3, using ChatGPT4:

No issue there, on a previously troublesome example. The witch floats.
We could proceed through the rest of Mitchell’s examples but, at this point, I think the pragmatic thing to do is to ask ChatGPT itself to write a program that reads old articles and updates the findings automatically. And to editorialize, it might be high time that the academic community took the necessary technological steps needed to write articles that do not go stale faster than bread (not so easy, I tried).
Mere patterns in data
Court cases aren’t decided only the facts, unfortunately, and the defendant’s fate might be influenced by the rhetorical power of words and phrases like “mere patterns”. (I think we can all appreciate the irony of ChatGPT losing its case based on overly verbal “reasoning” by the jury.)
Richard Hofstadter is another believer that genuine understanding extends beyond “statistical patterns in data”. But that kind of slant can deceive, in my view. It conjures baseball statistics, or technical analysis of stocks, or the kinds of things that the summer intern might discover given enough pizza and pandas.
The truth is we humans have very little intuition for high dimensional space in general (very much the lesson of mathematics) and for high dimensional statistics in particular (ask ChatGPT4 about it). We simply have no license to extrapolate what cannot be achieved deep in the bowels of a massive statistical machine, from what we can grasp about much smaller ones.
I’m skeptical that ChatGPT4 reasoned here:

There is a story involving Feynman where I take that puzzle from. He wasn’t entirely sure of the answer and nearly destroyed a lab finding out. Of course, the story would have made its way to the training set but, nonetheless, this is a strikingly coherent response from something LeCun regards as dumber than a cat. One example doesn’t move us. A torrent might though, and it is coming. Here’s another drop in the bucket
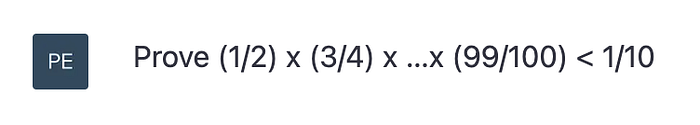
When you ask GPT4 for a solution, it might not find the shortest or most elementary path … but it will find different ways to approach the problem using different groupings of terms. One nice solution it presented me calculated the arithmetic mean of the left hand side (grouping 1/2+99/100 etc to show it exceeds 1/2). It then applied the arithmetic-geometric mean inequality: a nice mix of on-the-spot thinking and use of machinery.
There can be some deception and rote learning here too, I grant, but I think we should dispense with the notion that statistical machines are inherently limited in some kind of obvious manner by construction. I challenge anyone to push the reductionist line of argument there that ChatGPT4 could not itself poke holes in. That isn’t to say that there are other paths to intelligence, but my client is not on trial for being the second best thinking machine.
Of note, much of Judea Pearl’s work has been devoted to the explicit construction of mathematical mechanisms for encapsulating causal understanding, and Pearl is skeptical of LLMs ability to obviate those tools. (But I’m hoping that I can escalate his seeming conflict of intellectual interest in the eyes of the jury.)
Ernest Davis, a computer scientist and professor at New York University, has also argued that reasoning about the world and understanding natural language require explicit knowledge of facts, rules, and assumptions about how the world works. Lack of facts, lack of interaction and lack of structure of some kind might be fatal. Those representations exist in the brain, presumably, but not in LLMs of the near future.
It is all plausible, I suppose, and yet it sets us up to expect that LLMs will forever stumble over questions like “can a man marry his widow’s sister?”

Thing is, you can ask GPT4 if a bird can fly to the moon, or if a bee hummingbird can balance a scale with a single pea on it. Neural networks are pretty good universal approximation devices, as is any part of a neural network, so one should be cautious in stating what they cannot do.
Puzzles aside, the domain of programming is quickly becoming the venue where more and more people are experiencing the “wow” moment. Importantly for many of us, you can ask LLMs all manner of highly technical questions about bespoke programs you only just created. You can ask about programs it hasn’t seen. Its context inference is astonishing.

Many of you know what I’m talking about, even if words mostly fail me here. The new way to develop makes us feel like Tom Cruise in the Minority Report, tossing sections of code left and right with abandon and then sitting back amazed when it runs first time. (Or when it doesn’t, lobbing it the stack trace or nudging it with a few hints). This is the first time in my programming career I’ve ever been tempted to try voice recognition.
Whether my client gets off may depend on whether the jury is prepared to extrapolate LLM performance stochastically from evidence like this, and find enough probability mass in the tail to constitute reasonable doubt. They must choose to view it as an ongoing scientific accomplishment deserving more than petulant Amazon reviews. One cannot reject all evidence of flaws though, and I’m sorry if an incorrect response to a question robbed the reader’s alma mater of a basketball championship in 1987.
The space of all possible responses to an open-ended natural language question as a truly massive universe, and the task of landing a precisely correct one is like making a hole-in-one on Mars when teeing off from Venus. You have to be able to hit a ball from Mars to Venus first, and that’s what we’re seeing for the first time. What comes next? Who knows?
The ability to “understand” niche areas where supervision data exists and goals can be set and stumbled towards by LLMs is also fertile ground. Of interest to me: ChatGPT is perfectly capable of devising new type of forecasting models, or combining existing ones.
The interaction with the “real” world is fairly trivial to arrange, since LLMs can compete anywhere that kind of task is judged — such the stock market potentially, in betting markets, in data science contests like Kaggle (or Microprediction per my demonstration) or anywhere autonomous assessment is achievable. Or watch the demo video of a goal-driven autonomous use of ChatGPT in the Auto-GPT repository.
Just to go really meta on you, have a glance at the 180 lines of code here that is sufficient to send ChatGPT4 on a mission, and tell me that ChatGPT4 couldn’t have written it too, or written code to optimize a suite of different meta-strategies. Same for other LLMs, of course, making Facebook’s change of name quite appropriate.
So, is it really possible, at this stage, for us to mentally extrapolate to a world where the LLM’s have forked into interacting species, written their own meta-meta-programs, and found for themselves supervision data in far richer variety than they presently do?
What if those venues pretty much force LLMs to acquire notions of causality, in order to economically survive? I am personally more sympathetic to the view that more immersion is important, than to the supposition that the architecture is itself fundamentally inadequate.
Beating Kaggle may not be everyone’s idea of general intelligence (nor chess, or rhyming) but imagine the parallel possibilities for reward-based collective intelligence amongst dreaming bots of all kinds who form economic relationships. A future prediction web described here might provide a trillion “y’s” to aim at and billions of “experiences”.
As I’ve also noted ad nauseam and in this book, we don’t have a highway on which algorithms can travel to business problems (yet). If we did, multiple copies of language models could engage in various kinds of play at once, all pursuing interesting things and seeking intermediate rewards of different design.
Imagination
I suspect that as performance improves, human exceptionalism will retreat further. Kasparov might be the one to argue that even after logical processing and reasoning is conceded, and even after GPT4 has refuted the Halloween Gambit over the board there will still be a uniquely human realm of creativity and imagination.
For now, Garry Kasparov is apparently impressed with Gary Marcus’ ability to determine what “AI is not”. This is surprising. Even in the tiny pocket of the universe called chess, never mind other vast expanses, it isn’t obvious. I just have one question for Mr Kasparov: what would you have played here?
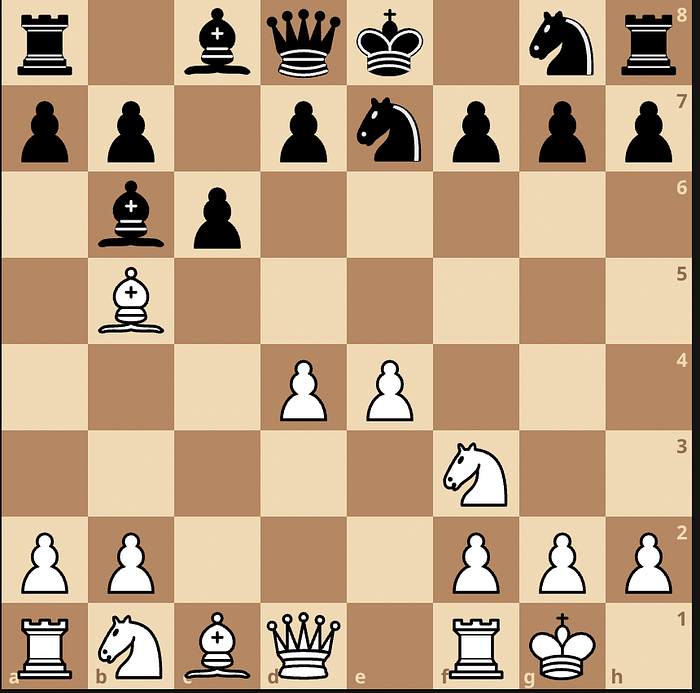
There is a parallel between the Lemoine variation: “maybe this thing has real intelligence …. whaaaatt?!” and the “just gonna hang that bishop ’cause nothin’ doing” Leela variation in the Ruy Lopez — as it should be called hereafter, see the game. Like ChatGPT Leela has a fuzzy brain but the moved played here — perhaps the first in the history of the game to warrant a triple exclamation mark — strongly suggests that representations forming in her network are quite “deep”, in the chess sense. Calculation only goes so far.
(I’m sorry if 8.d5!!! doesn’t light up your central nervous system)
I’m not saying Lemoine was right, just that his brain was able to avoid pruning the search tree the way we all do. But from my perspective it is almost impossible for our chess vision to take seriously the fact that 8. d5 should be considered against a 3500 Elo opponent in a tournament game.
Neural networks are sneakier than we think, maybe. Some views:
- Gary Marcus. AI needs to be rebooted before it can win.
- Garry Kasparov. Deep Blue needed to be rebooted before it could win.
- Dude whose blog you are reading. If we are so stuck in a rut we can’t consider the possibility that LLMs are intelligent, we need to be rebooted.
It’s almost beside the point that every business model on Earth currently needs a reboot too, or is in denial. But such low-brow considerations might be beneath our philosophical perch. Let’s stick with creativity specifically:

I nearly fell off my perch when it came back with “octopus”, incidentally, because that was the name given to a Bayesian filtering algorithm developed by a quant Erik Closson at my old company.
Protolanguage
You see, I hope, that I do not wish to run from claims made by Michell or anyone else about the existence of non-verbal mechanisms of thought, or representations of world structure internalized by our brains extending far beyond language. That would be a most peculiar position for a blitz addict of mathematical bent to hold.
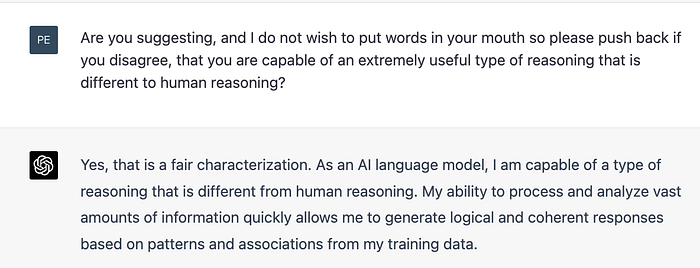
I expect the jury to laugh off Marcus’ suggestion that machines cannot bring together ideas from many sources, cross-validate them and reach novel conclusions (while the judge secretly taps out questions into an Open AI app under the desk). But the court case may rest on whether LLMs are considered to be fundamentally limited because they simply operate in the wrong space: text and language only and — as Chomsky or others might testify — do so superficially.
We are to believe that LLMs will never see the fundamental particles, as it were and therefore will not truly grok the “physical laws” (I mean that generally). They can only fake it, having observed millions of cloud chamber paths. They can simulate their own paths but this isn’t “real understanding”, that line of reasoning goes.
But let’s take the incompleteness of language head on. Let’s agree that language is just one example of the brain’s ability to construct representations and maybe not the most important one. For surely there are others that evolved including non-verbal things that, perhaps by their natures, we might never be able to force onto this page — or only do so partially.
In keeping with our theme, Magnus Carlsen’s drunken rampages through the bullet chess World Championship (story) provide the most amusing, if not the strongest, evidence of a separate spatial processing engine — one whose operation is largely untaxed by a stream of self-commentary emanating from his Broca’s area. The Carlson chess engine probably bears more similarity to vision and engages different areas in the cortex as well. That machine is, judging by results, less affected by beer and vodka consumption than speech is, or motor skills (too soon Magnus?), and thus likely to be a separate function.

In the “we got it going on in there” view, which is the more reasonable, language is a crux for some higher thought sometimes but also evidence of something else we don’t yet understand. Plenty of other things.
But … but … it is still reasonable, more than reasonable actually, that the mysterious structures and abilities have some similarity to, and certainly communication with, language production. It is plausible, more than plausible in fact, that LLMs can learn to “think”, even if they only see doubly noisy, once-removed evidence of hidden structure in the brain.
They might approximately learn that queens can move on diagonals but not through pawns, for instance. I say approximately because this seems obvious from the architecture — but also because in one game I played against ChatGPT4 it literally jumped a queen over a pawn.
Referencing Lupyan again, a blind person understands that you can see through water, or a glass you might drink water out of. Lupyan turns the prejudice against machines we might have on its head by noting “a blind person talking about transparency is not a stochastic parrot”.
For this reason, to return to the physics analogy, all those cloud chamber paths left by humans are more valuable than we realize— not for their literal facts, nor their ability to annoy Chomsky with flawless grammatical performance, but because they betray non-verbal mechanisms in the brain that we use to produce creative ideas, or music, or mappings of the platonic universe, or common sense.
Those mechanisms are different, sure, but not always completely so. It’s worth noting briefly the long history of people drawing tight relationships between language and thought. As with Mitchell, Derek Bickerton posits protolanguage as a precursor to richer communication (“Language and Species”). That protolanguage might have served cognitive functions such as facilitating planning and problem-solving.
Perhaps we even “thought out loud” by talking to ourselves. I’m reminded of Consciousness Explained where Daniel Dennett suggests that language might have initially helped individuals to structure and process their thoughts before it was co-opted for communication purposes. Psychology brings related ideas such as private speech coined by psychologist Lev Vygotsky to refer to the self-directed, externalized voice that young children use to guide their own behavior and cognitive processes.
In this style of theory, speech eventually becomes internalized and transforms into inner speech, or internal dialogue, which continues to guide thought and behavior. But if one transition is possible, why not another from there, deeper into the brain, and so on? From that perspective learning deep things from language starts to look like a practical challenge (a. la. vanishing gradients) not a profound roadblock.
Are we that smart?
Naturally, I am trying to sow doubt in the mind of jury members by positing a possibility outside the picture painted by the prosecution. Mine need not be proven beyond reasonable doubt, and I’m sure Geoffrey Hinton, who is disinclined to rule out Artificial General Intelligence (AGI) within five to ten years, could come up with better ones. What a wonderful foreperson he would make.
For others even a little doubt is trickier. Remember when Roger Penrose told us AGI it would probably require a quantum computer? The notion that human intelligence might be unravelled one automatic derivative at a time, using a pile of discarded Ataris in a pinch, is as terrifying as the idea that the Earth is not the center of the universe.
As evidence of this sheer horror, I note that proclamations of the specialness of human reasoning are invariably greeted with rounds of applause on social media — even if they are completely circular and serve only as a reminder that there are actually two possibilities: LLMs will be much smarter than we think, or we aren’t that smart to begin with.
That’s why I feel some mental model, however speculative, should be posited down that second line (with great temerity, but in the best interest of my client) and I’ll adopt an engineers perspective that seeks to trivialize us as … vacuum cleaners.
Let’s run further with a working approximation: that intelligence is “navigation through abstract spaces and representation thereof” and the brain is, in part, a glorified filter — an unscented Kalman filter if you insist on a tad more metaphorical precision at the likely cost of accuracy. It is a machine that throws up many possibilities, constantly, and then aggressively filters them as evidence arrives (flight path one of ball, flight path two of ball, dumb business plan one, dumb business plan two,…).
The brain can do the generation so efficiently that it could quickly fill a universe of fake worlds — a spray of ball trajectories like a fireworks display, or images like DALL-E or “thoughts” like ChatGPT. Yet it reins this in, somehow. And it is brilliant at this data assimilation. It focuses on changes coming from external or internal stimuli, naturally, but can do this in dimensions we can’t grok. I don’t know how it does it, but perhaps LLMs are positioned to do something similar. It isn’t structurally impossible.
I’m less worried, in this mental model, about exams thrown at LLMs that it fails — if this doesn’t preclude navigation by other means. First order predicate logic might be useful in this task, or castling rules, just as constraints or physical models can help a Kalman filter if you are lucky enough to know what they are. But they are not essential.
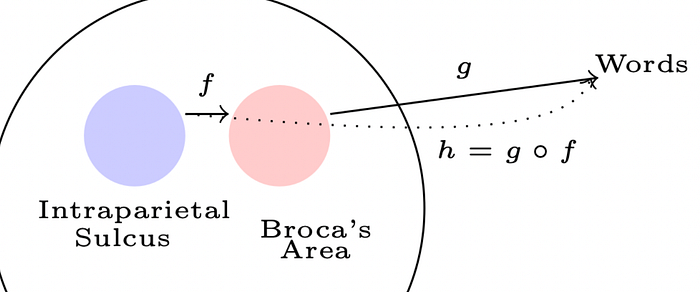
As I have schematically represented, (not knowing a wit about neurology to be honest) there is presumably a composition of observation functions. One map denoted “f” takes us from some unknown forest of representations in the brain to language processing, and a second observation function “g” is the reflection in words, or equations, on a page. The composition h is surely intriguing.
Though this is highly stylized, and though there is no doubt a huge amount of corruption on the long path from “understanding” (mysterious structure) to “words”, it is nonetheless a stream of observations (with noise, of course). With sufficient evidence, that latent structure must eventually be revealed, I am tempted to think — though I need only convince the jury that it might be revealed.
To be trite, a modern day navigation system fed noisy data is “merely finding patterns in data” and “merely computing the distribution of future observations” that are themselves not “true”. But that doesn’t mean it isn’t constantly trying to converge on an underlying reality, or that physics isn’t being discovered and understood through the haze (or could be, depending on what is updated).
In our analogy however, it is a little different because it isn’t necessary to determine where the rocket is. The rocket is the inner state of our brain or a point in some wacky representation that our roving consciousness flicks to momentarily. The “truth” is understanding, and that lies in a different space: an equivalence class of brains.
It would be perfectly fine if something else were to be implied instead by an LLM— some set of representations conspiring to create mostly similar observations, predictions and conclusions. The peculiarities of human thinking and the unfathomable architecture of the brain pose an “identification problem”, to use systems vocabulary (c.f. qualia, Wittgenstein, symbol grounding problem, etc) but that doesn’t mean machines can’t also understand, or in that sense be like we are.
UPDATE: Oct 2023. Please see the fascinating paper Language Models Represent Space and Time (pdf) by Wes Gurnee & Max Tegmark which strongly supports this general line of thought.
UPDATE Dec 2024: See this related paper on Platonic convergence in LLM representations.
Where’s the magic?
Now yes, this is hardly fleshed out. It’s just the burglar theory whose vague outlines hope to get the husband acquitted, more than anything else, but I’m not the one trying to prove a negative.
If my kids were to ask me what intelligence is, my answer would as defensive and as coy as ChatGPT: something like “I am only a parent and I do not know the true nature of things and I only remember facts vividly up until about 1998”. But when they click the regenerate button I am forced into some kind of explanation, just as I am to try to raise doubt in your mind. So we have the piloting analogy and the sneakiness of the brain emerges as a spin on the famous wisecrack:
There are only two hard things in Computer Science: cache invalidation and naming things — Phil Karlton
The brain is intelligent — I shall tell my kids one day when they finally ask — because it has solved the one hardest problems in computer science. Get it? I’m saving that dad joke in the fine tradition of referencing Karlton although ChatGPT4’s effort is better:
Why did the computer scientist’s band break up? They couldn’t decide whether to name their first album “Cache Invalidation” or “Naming Things”
Here “naming things” is code for representations extending beyond language. And cache invalidation is really hard too, especially if the cache is a very sophisticated set of representations of all manner of things in all manner of guises, some literal, some spatial, some abstract, whose re-use might occur by analogy only, or by some mechanism we do not understand. How does the brain know what to ignore, and what to refresh, what to recycle, and how to manage state?
Why don’t you think my joke is funny? Because it doesn’t help your brain hop from one level to another, I speculate wildly. I’m assuming that humor has something very vaguely to do with cache priority of higher level representations, or functors from one space to another if you will, or maybe even evolutionary relics sometimes. We laugh to get better at abstraction, just as we get better at remembering to ride a bike if we fall and a pain signal is sent to the brain (that’s what I told my daughter, anyway, without chat-checking). Attention is all we need.
The brains filtering ability evolved over long time frames no doubt, and evolves in a different way as we grow too. It impacts our perception of the passage of time. We are sometimes jaded with life, or our work, and we cannot remember arbitrary labels like people’s names. As we strive to become better at navigating more and more abstract spaces, perhaps we need to store representations in more and more efficient, high level ways. (This part is met by eye-rolls from the missus).
In the trial of LLMs the burden of proof lies not with those who assert there are connections between language and other brain capabilities. The defense team certainly doesn’t understand the relationship between reason, thought and our own language. Nobody does. But to reiterate the mere existence of a connection, which of course is more than plausible, implies in this analogy that LLMs are “observing thought” — whatever that might be.
Hypothesize, for example, some pattern in the brain or function previously used for pre-language that has long since morphed and adopted a different role. It now participates in what Hofstadter called “strange loops” — a phrase I was reminded of reading John Hogan’s reflection on thoughts and meta-thoughts and bumbling through the day here.
We would be brave to assert the opposite position: that language ends somewhere and patterns in text and our descriptions of the world do not betray deeper meaning. I would like someone who is sure machines can’t be intelligent though indirect observation en masse explain the cloaking mechanism they have in mind.
Streaming consciousness
There are lots of ways to try to make filtering more efficient. Some we know from statistics and engineering. Others are philosophical speculations. The Multiple Drafts Model, returning to Daniel Dennett, posits there is no single, unified stream of consciousness. Instead, it suggests that our brains consist of multiple parallel processes that compete for attention, with some processes eventually being incorporated into our conscious experience, while others fade away.
That’s easy to mashup with a Kalman filter, isn’t it? You don’t know my precise prompt here. There’s an equivalence class of them.

ChatGPT’s ruminating might be closer to the “Thousand Brains” model of Jeff Hawkins which is specific and operational. That also positions the brain’s construction as an algorithmic optimization of sorts, where the neocortex is composed of numerous small modules called cortical columns that learn to model different aspects of the world independently, forming a representation of objects and concepts.
These columns then vote on the overall interpretation of sensory input, effectively creating a consensus on what the brain perceives (He’s wrong about the voting they use biological parimutuels, obviously). Over time though, one kind of reference frame — say the relative position of your cup and hand — might get reused in a surprising way that has nothing whatever to do with motor control.
Let’s emphasize the abstractness of the navigation. Even if we get down on the floor and play the robot cleaner it will be the case that one level of representation is inadequate: such as a spatial representation of the house. The paucity of that map is evident the moment we suck up a discarded hair band and grind to a halt. Escaping that maze draws on an entirely different perspective. Our minds are not traversing the kitchen floor, but far stranger territories akin to the folded spacetime dimensions of a Liu Cixin novel.
The oft-applied LLM label “Autocomplete-on-steroids” can look like underselling, if that’s what we are, too. If you can autocomplete in very abstract ways, and in many different ways at high speed, and also filter, you can really get around. You can appear devious, and astute, and creative. Especially if most of the arriving data points are coming not from the outside world but instead are being thrown together by different parts of the brain ceaselessly. We have our best ideas, sometimes, in the half-conscious state before fully waking up.
For me that’s the key part of Hawkins’ assertion: that the neocortex learns abstract representations and these can be applied to different contexts — completely different contexts that may not even feel like they are of the same type. Some are embedded in the physical three dimensional world but some are not. These representations help me built models of hair-band ownership, and make decisions in real-time about who to berate, as I extract the tangled remains from the rotor. So too, LLMs might learn to be high dimensional Roombas some day, if they haven’t already.
Lies, damn lies, and statistical hallucinations
But yes, the hallucinations.
The prosecution will hammer on that point, won’t they? It is very evocative. When used less formally outside a medical context the term is a way to put down people (or their ideas) as unrealistic, wrong-headed, outright crazy, or at minimum unfinished. I’m reminded of someone I used to work for whose corporate mantra was “vision without execution is hallucination”.
The negative tones seem like a distraction to me in the LLM context, even if some think “hallucination” isn’t negative enough (or careful enough due to the implied personification, deemed a priori ridiculous). Arthur Juliani in an article titled Large Language Models Don’t Hallucinate suggests that “bullshitting” or “confabulation” are more appropriate alternatives. I won’t be calling him to the stand.
I think there is a sly confirmation bias lurking for those who believe machines can’t reason or lack common sense because they (increasingly less frequently) throw up nonsense. Dismissing false answers is especially easy to do when the result is a simple factual error, such as the year of publication of a paper or a purely invented author. The output looks like it is a narrow statement whose paucity conveys the absence of intelligence.
If that answer were delivered from a rule-based system it would be one thing. But we know, from construction, that the answer emerging from an LLM is very far from a lookup (you can’t have it both ways: criticizing LLMs for having “floppy” representations of logic but implying drastic implications of errors as if they were rigid). LLM hallucinations are the output of an extremely complex network with odd emergent properties — such as the ability to successfully make useful programming analogies, infer bugs in code it hasn’t even seen, and so on.
I’m not suggesting that every error is a deep blunder. But drawing the accurate inference from any given “hallucination” is not always trivial. Perhaps we owe it to LLMs to try to make an effort and figure out whether a given hallucination might have been more meaningful in another context (rather than dismissing them as merely “trippy”). Snap judgements may belie our own lack of dexterity in jumping from one reference frame to another.
Pushing back on the negative connotations of “hallucination” in humans might also help my client just a little. Let me start by pointing out that hallucination is considered by some to be indirect evidence of differentiating brain characteristics conferring survival advantage, or indirect evidence of the same in close relatives, or more tenuously might even be a survival advantage itself.
I hasten to add that my adoption of the “hallucination” terminology for LLMs, and with it the mapping to humans, isn’t one I particularly like — but it merely references Yann LeCun and others’ choice of words. As with “mere statistical patterns” it is a verbal tactic to encourage us to see hallucination as a symptom of an underlying illness in LLMs that must be cured or driven from the population.
Yet LLM hallucination might instead be something that stays in the gene pool forever well after machines are universally regarded as intelligent. It may reach an equilibrium that takes into account its obvious pitfalls but also the following considerations:
- A less pruned search can be useful.
- Hallucination in one domain might represent real structure in another.
- Hallucination may be correlated with some abilities (I don’t know why).
The first point barely needs mention. You don’t have to be the late John Nash (cue speculation on genius) to notice the rather obvious line of thinking: those that are capable of generating novel thoughts might have an advantage in some regards, even if the vast majority of those directions are implausible gibberish, or would be if it was even possible to project them from whatever abstract space they live in back to language.
And although using an Octopus to predict a time series might initially sound ridiculous, there may indeed be some way to trick it into performing a useful operation. There might be octopus computers that can factor the number 8 using less energy than it takes to store the number 8 in a community database (that’s your subtle hint that my LLM infatuation does not arise from a predisposition towards hyped technologies generally — don’t even try it on me).
Even Kasparov should be sympathetic, since he was constantly forced to check that extra ply or two, and not prematurely dismiss possibilities. Us mortals are lazier, and miss things that greats might analyze — such as a Karpovian retraction of a knight to the first rank that seems to waste time, or a Fischerian move that allows the opponent to break up our kingside. Elsewhere, something that violates a maxim, or gets trapped by the mental equivalent of a feature-selection rule, is a possibility lost.
I use the examples of Nash and Fischer to try to hint at the third reason, too, not because Fischer was ever officially diagnosed with a mental illness as far as I know, but because his behavior has suggested to some researchers that he might have been genetically predisposed. Is there a machine equivalent?
Since we’re being open-minded now, let’s observe that also that a least one condition where we see hallucinations in humans, namely schizophrenia, is notable because of its perplexing evolutionary stubbornness. Some researchers have suggested that individuals carrying one copy of a risk allele for schizophrenia (heterozygotes) may have certain cognitive or creative advantages compared to individuals without the risk allele.
(This area is an extremely messy though, it must be said. The consensus view is that schizophrenia’s genetic influences are very complex indeed — and some have pushed back on the evolutionary story due to the relatively late onset.)
Perhaps I’m a little more sensitive to pejorative use of the term “hallucination” because I have had significant personal exposure to schizophrenia — though I don’t personally suffer. All the recent talk of LLM hallucination reminded me of a work by David Horrobin back in 2001: The Madness of Adam and Eve: How Schizophrenia Shaped Humanity. It had sat on my bookshelf for a long time when I was looking for any possible upside on the horrid robbing disease, and wondering why it hadn’t died out.

Horrobin argued that the same genetic factors that predispose individuals to schizophrenia might have also played a crucial role in the development of human intelligence, creativity, and complex social behavior. The rapid evolution of the human brain, particularly the expansion of the frontal lobes, might have been driven by a mutation in the genes related to fatty acid metabolism.
This mutation would have led to an increased availability of a specific type of fatty acid called arachidonic acid, which is important for brain function and development. ChatGPT4 is happy to speculate down the lines of Horrobin (with just a hint about the role of a change in diet in my prompt, also an important part of Horrobin’s thesis).
A change in diet and the shift from a hunting and gathering lifestyle to an agrarian culture may have played a significant role in the development of these genetic factors. As humans transitioned from a predominantly meat-based diet, rich in essential fatty acids like arachidonic acid, to a more plant-based diet with the advent of agriculture, the availability of these fatty acids might have decreased. This dietary change would have exerted selective pressure on the human population, favoring individuals with genetic mutations that facilitated the increased production and utilization of essential fatty acids, such as arachidonic acid.
The increase in arachidonic acid availability might have had a substantial impact on brain development and cognitive function. Arachidonic acid plays a vital role in the formation of neuronal cell membranes, modulation of neurotransmitter release, and regulation of synaptic plasticity. Consequently, the mutation in fatty acid metabolism genes would have facilitated enhanced brain function, leading to the rapid development of intelligence, creativity, and complex social behavior in humans.
Speculative? Absolutely. And yet if Horrobin is eventually proven half right there will be a stunning symmetry in the development of both human and artificial intelligence. Looking back we might view hallucination more positively, and associated with a step-function improvement in cognitive ability of both species.
We might be the real suckers
You scrolled down, right? I don’t blame you and here’s where my head is at just in case anyone cares:
- The dismissive reductionist case isn’t much more than an article of faith at this point. As Sebastien Bubeck says in this fascinating talk, beware the trillion dimensional space!
- The grounding argument has surprised on the downside, empirically, for now. It runs counter to the experience of sense-deprivation in humans, and more doubt is created by the related point 4 below.
- The neural network representation argument or the call for “more rules or logic” is a hard one to make, given the approximation qualities of neural networks and the fact that London is, apparently, in England.
- And finally, what I have called the “cloaking” argument is underdeveloped at best. If there is a strong reason why “deep” representations in the human brain cannot eventually be betrayed by language alone, I don’t think anyone has made the case carefully (yet).
This intriguing time in human engineering doesn’t seem to me to be the moment to casually pooh-pooh pre-trained generative transformers for having the temerity to be, well, generators. With LLMs we get the Steve Jobs “think different” creativity, with perfect grammar.
It probably isn’t a good time to start an AI eugenics movement with strong preconceptions about what constitutes explainability, accuracy, knowledge or utility either. It would better to reflect on the development of human intelligence and look upon the ability to “half-way plausibly sample from the distribution of all that may or may not be true incredibly well” as a harbinger of even more surprising things to follow.
If making things up and tossing structure from one room to another is key to our own intelligence, the joke might be on us if we downplay the artificial kind of intelligence because we lazily “autocomplete” existing, possibly stale, philosophy.
Maybe someday Large Language Models with better perception than us will let us know in no uncertain terms, and with a scientific condescension we richly deserve, that we’ve been kidding ourselves all along with our mysticism. The specialness of human intelligence might turn out to be the ultimate hallucination.

